[ML Study]ch05-2 교차 검증과 그리드 서치

본 포스팅 한빛미디어의 <혼자공부하는 머신러닝+딥러닝(박해선 저)>를 요약 정리했습니다.
검증 세트
테스트 세트를 사용하지 않고 과대적합인지 과소적합인지 판단하기 위해 훈련 세트를 나누어 검증하는 것을 말한다.
검증 세트를 몇 %만큼 나누어야 적당한가?
-> 보통 20~30%를 나누지만 훈련 세트가 많으면 많을 수록 더 적게 나누어도 문제가 발생하지 않는다.
교차 검증
검증 세트를 만들게 된다면 훈련에 사용되는 데이터가 줄어들게 된다. 하지만 대부분 데이터를 많이 훈련하면 좋은 모델이 만들어진다. 그러므로 교차검증을 이용하여 이러한 문제를 해결한다.
- 교차 검증: 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복한다.
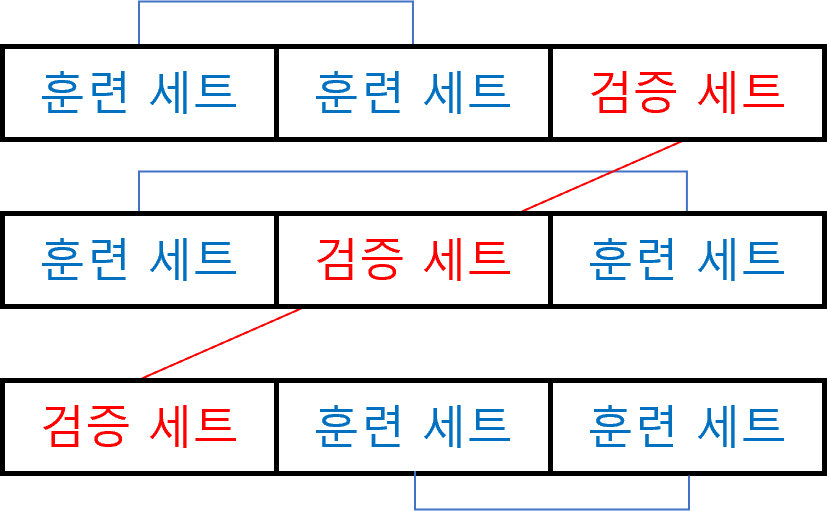
k-폴드 교차 검증(k-fold cross validation)은 k부분으로 나눠서 교차 검증을 수행하는 것을 말합니다.
sklearn.model_selection.cross_validate(estimator, X, y=None, *, groups=None, scoring=None,
cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', return_train_score=False,
return_estimator=False, return_indices=False, error_score=nan)
cross_validate는 사이킷런에서 제공하는 교차 검증 함수이다. cross_validate 함수는 교차 검증 검사를 통해 메트릭을 평가하고 fit/score 시간도 기록한다. 기본적으로는 5-폴드 교차 검증을 수행하는데 위에 cv를 변경하여 폴드 수를 변경할 수 있다. 그리고 대표적인 매개변수로는 다음과 같이 존재한다.
- estimator: ‘fit’을 구현하는 객체
- X: 훈련할 데이터(train Data)
- y: 예측을 시도할 데이터(train 정답)
- groups: 데이터 세트를 훈련/테스트 세트로 분할할 때 사용되는 샘플의 그룹 레이블이다.
- scoring: 테스트 세트에서 교차 검증 모델의 성능을 평가하기 위한 전략이다. (input: single string, callable, str list tuple…)
- cv: 분할 전략을 결정한다. (default(5) or 분할할 개수 입력) 등등 매개변수에 대해 더 궁금하다면 공식문서를 참조하기 바랍니다.
class sklearn.model_selection.StratifiedKFold(n_splits=5, *, shuffle=False,
random_state=None)
cross_validate() 함수는 회귀 모델일 경우에는 기본적으로 KFold 분할기를 사용하고 분류 모델일 경우에는 StratifiedKFold분류기를 사용한다. stratifiedKFold는 훈련/테스트 세트에서 데이터를 분할하기 위한 훈련/테스트 인덱스를 제공한다. 이 객체는 KFold의 한계를 극복하기 위해 생겨났고 KFold와의 데이터셋을 무작위로 섞은 것은 똑같지만 다른점은 각 클래스의 비율을 고려하여 K개의 폴드로 나눈다. 그러므로 데이터 불균형한 경우 각 폴드가 모든 클래스를 적절하게 반영한다.
- n_splits: 나눌 개수이고 값은 2이상이여야 한다. int, default=5
- shuffle: 분할하기 전에 각 클래스의 샘플을 섞을지 정한다. bool, default=False
- random_state: shuffle이 True인 경우, 이 변수의 값에 따라 무작위성을 제어한다. int, default=None
하이퍼파라미터 튜닝
머신러닝 모델이 학습하는 파라미터를 모델 파라미터라고 부른다. 모델이 학습할 수 없어서 사용자가 지정해야만 하는 파라미터를 하이퍼파라미터라고 한다.
하이퍼파라미터 튜닝 방식
- 라이브러리가 제공하는 기본값을 그대로 사용해 모델을 훈련한다.
- 검증 세트의 정수나 교차 검증을 통해 매개변수를 조금씩 바꿔서 진행한다.
class sklearn.model_selection.GridSearchCV(estimator, param_grid, *, scoring=None,
n_jobs=None, refit=True, cv=None, verbose=0,
pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False)
GridSearchCV는 하이퍼파라미터 튜닝을 자동화하기 위해 사용되는 기법으로 교차 검증, 그리드 서치를 결합한 클래스이다. 이 클래스는 사용자가 지정한 하이퍼파라미터 후보들을 가지고 가능한 모든 조합을 시도하여 최적의 하이퍼파라미터 조합을 찾아내고 교차 검증을 이용하여 조합의 성능을 평가한다.
- estimator: 하이퍼파라미터 튜닝을 원하는 모델을 지정한다.
- param_grid: 사용될 파라미터를 dictionary 형태로 넣는다.
- scoring: 모델의 성능 평가 지표를 선택한다.
- cv: 교차 검증을 위한 폴드 수를 지정한다.
랜덤 서치
만약 너무 많은 매개변수 조건이 있어서 그리드 서치 수행 시간이 오래걸릴 때 사용하는 방법은 랜덤 서치(Random Search)를 이용하면 된다. 랜덤 서치는 매개변수를 샐플링할 수 있는 확률 분포 객체를 전달한다.
사용하는 클래스
scipy.stats.randint = <scipy.stats._discrete_distns.randint_gen object>[source]
scipy.stats.uniform = <scipy.stats._continuous_distns.uniform_gen object>
randint와 uniform는 주어진 범위에서 고르게 값을 뽑아 균등 분포 샘플링을 한다. 두 클래스의 차이점은 randint는 정수값을 추출하고 uniform은 실수값을 추출한다. 매개변수들은 아래와 같다.
- randint
- low: 생성하는 정수 값의 최소 범위를 지정한다.
- high: 생상하는 정수 값의 최대 범위를 지정한다. (high-1까지 지정)
- szie: 생성할 샘플의 개수를 저정한다.
- uniform
- loc: 생성하는 실수 값의 최소 범위를 지정한다.
- scale: 생성하는 실수 값의 범위를 지정한다. (데이터에는 loc <-> loc + scale의 사이 값이 포함된다.)
- size: 생성할 샘플의 개수를 지정한다.
class sklearn.model_selection.RandomizedSearchCV(estimator, param_distributions, *,
n_iter=10, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0,
pre_dispatch='2*n_jobs', random_state=None, error_score=nan, return_train_score=False)
RandomizedSearchCV는 GridSearchCV와 같이 최적의 하이퍼파라미터를 찾기 위한 방법 중 하나이다. 이 분류기는 GridSearchCV와 다른게 모든 조합을 시도하지 않고 각 반복마다 임의의 값만 대입해 지정한 횟수만큼 평가한다. 그러므로 비교적 시간이 더 적게 걸린다는 장점이 있다.
- estimator: 튜닝을 원하는 모델을 지정한다.
- param_distributions: 하이퍼파라미터들을 dictionary 형태로 넣는다.
- n_iter: 랜덥하게 조합을 시도할 횟수를 지정한다.
- scoring: 모델의 설능 평가 지표를 선택한다.
- cv: 교차 검증을 위한 폴드 수를 지정한다.