[ML Study]ch06-2 k 평균
혼자 공부하는 머신러닝+딥러닝 [6-2]

본 포스팅 한빛미디어의 <혼자공부하는 머신러닝+딥러닝(박해선 저)>를 요약 정리했습니다.
K 평균
K 평균
- k-평균 알고리즘(K-means)은 주변 데이터를 K개의 클러스터로 묶어 평균값을 찾는 알고리즘이다.
- 여기서 K는 묶을 군집의 개수를 의미한다.
- k-평균 알고리즘이 찾은 평균값이 클러스터의 중심에 위치하기 때문에 클러스터 중심(cluster center) 또는 센트로이드(centroid)라고 부른다.
k 평균 알고리즘 작동 순서는 다음과 같다.
-
무작위로 k개의 클러스터 중심을 정한다.
-
각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
- 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
- 거리 상 가까운 군집(중심점)으로 주어진 모든 데이터를 할당 또는 배정한다.
- 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복한다.
이를 그림으로 나타내면 아래의 그림과 같다.
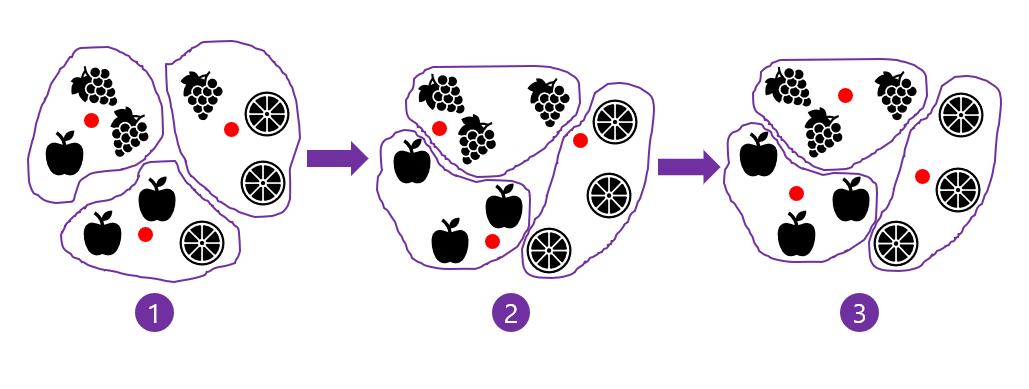
-
먼저 3개의 클러스터 중심(빨간 점)을 랜덤하게 지정한다.
-
그리고 클러스터 중심에서 가장 가까운 샘플을 하나의 클러스터로 묶는다.
-
왼쪽 위부터 시계 방향으로 클러스터가 만들어졌다. 클러스터에는 순서나 번호는 의미가 없다.
-
그다음 클러스터의 중심을 다시 계산하여 이동시킨다. 맨 아래 클러스터는 사과 쪽으로 중심이 조금 더 이동하고 왼쪽 위의 클러스터는 포도 쪽으로 중심이 더 이동하는 식이다.
-
클러스터 중심을 다시 계산한 다음 가장 가까운 샘플을 다시 클러스터로 묶는다.
-
이제 3개의 클러스터에는 포도와 오렌지, 사과가 3개씩 올바르게 묶여있다. 다시 한번 클러스터 중심을 계산한다. 그다음 빨간 점을 클러스터의 가운데 부분으로 이동시킨다.
-
이동된 클러스터 중심에서 다시 한번 가장 가까운 샘플을 클러스터로 묶는다. 중심에서 가장 가까운 샘플은 이전 클러스터와 동일하다. 따라서 만들어진 클러스터에 변동이 없으므로 k-평균 알고리즘을 종료한다.
이렇게 k-평균 알고리즘은 처음에는 랜덤하게 클러스터 중심을 선택하고 점차 가장 가까운 샘플의 중심으로 이동하는 비교적 간단한 알고리즘이다.
사이킷런의 k-평균 알고리즘은 sklearn.cluster 모듈 아래 KMeans 클래스에 구현되어 있다.