[ML Study]ch07-3 신경망 모델 훈련
혼자 공부하는 머신러닝+딥러닝 [7-3]

본 포스팅 한빛미디어의 <혼자공부하는 머신러닝+딥러닝(박해선 저)>를 요약 정리했습니다.
신경망 모델 훈련
손실 곡선
- fit() 메서드로 모델을 훈련하면 훈련 과정이 상세하게 출력되어 에포크 횟수, 손실, 정확도 등을 확인할 수 있다.
- 그런데 아래와 같이 출력의 마지막에 다음과 같은 메시지가 출력되는 것을 확인했을 것이다.
tensorflow.python.keras.callbacks.History at 0x7f11f82f5710
위 메시지는 fit()메서드의 실행 결과를 출력한 것이다. fit() 메서드는 History 클래스 객체를 반환한다. History 객체에는 훈련 과정에서 계산한 지표, 즉 손실과 정확도 값이 저장 되어 있다. 이 값을 이용해 그래프를 그려 얼마나 손실 했는지, 정확도가 얼마나 향상하는지 확인할 수 있다.
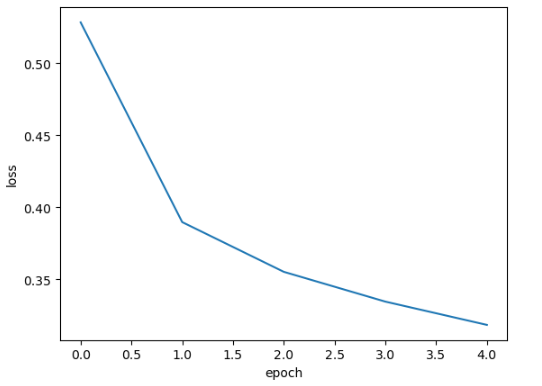
위 그래프를 보면 에포크 횟수와 손실 값을 확인할 수 있다. x축은 에포크 횟수, y축은 계산된 손실 값이다.
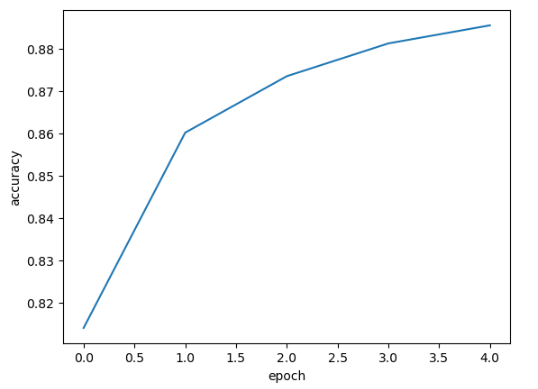
위 그래프는 정확도를 출력한 것이다. 그래프를 보면 에포크마다 손실이 감소하고 정확도가 향상하는 것을 볼 수 있다.
이를 통해 에포크를 늘리면 손실이 감소할 것이라 판단하여 에포크 횟수를 늘려 훈련을 진행한다.
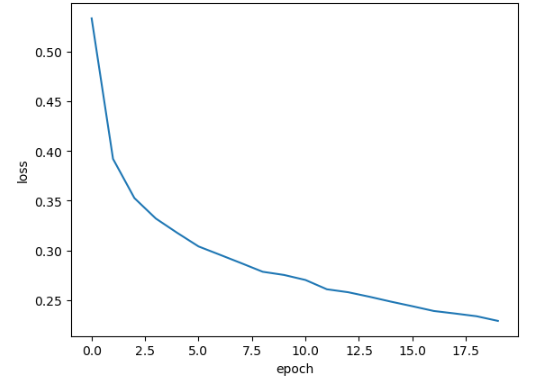
예상대로 에포크 횟수를 늘리니 에포크마다 손실이 감소하는 것을 확인할 수 있다.
검증 손실
에포크에 따른 과대적합과 과소적합을 파악하려면 훈련 세트에 대한 점수뿐만 아니라 검증 세트에 대한 점수도 필요하다.
따라서 훈련 세트의 손실만 그리는 것이 아닌 검증 세트에 대한 손실을 그려 파악해야 한다.
만약 그래프를 그린다면 아래와 같은 그래프가 그려질거라 예상한다.
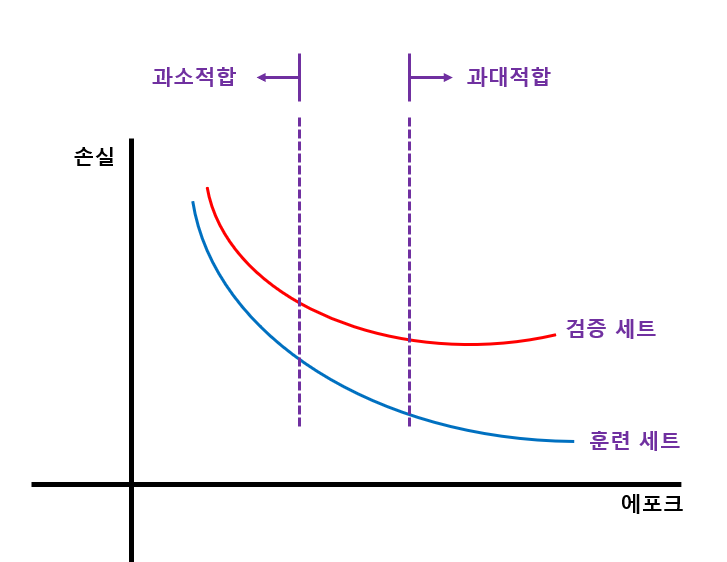
과대/과소 적합 문제를 보기 위해 훈련 손실과 검증 손실을 한 그래프에 그려서 비교한다.
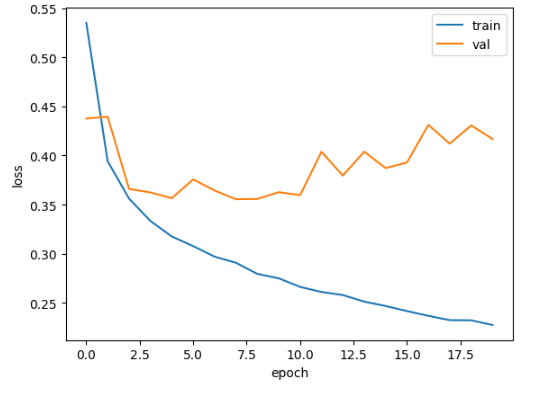
그래프를 보면 초기에 검증 손실이 감소하다가 다섯 번째 에포크 만에 다시 상승하기 시작한다.
훈련 손실은 꾸준히 감소하기 때문에 전형적인 과대적합 모델이 만들어진다.
검증 손실이 상승하는 시점을 가능한 뒤로 늦추면 검증 세트에 대한 손실이 줄어들 뿐만 아니라 검증 세트에 대한 정확도도 증가할 것이다.